自定义规则支持正则表达式提取、JS脚本自定义提取、简易左右文本提取方式提取网页中的数据。
自定义字段功能仅限企业版旗舰版以上用户使用,其他版本暂时无法使用该功能
注:我们售后不包含代写自定义规则的服务,也没办法教您正则表达式、JS代码编写,因此请您自行学习这些技术,若需要我们代写需要按情况收取费用。您也可以将您需要采集的字段反馈给我们内置支持。
什么自定义字段
通过自定义字段,可采集本软件没有内置的字段数据,配置采集自己需要的数据,大大提高采集面。
由于本软件使用自研采集引擎,并非通过浏览器的方式采集,因此系统不支持操作HTML document对象、不支持JQ、不支持Xpath、只能通过对网页源码进行正则提取、文本标记提取、普通JS脚本执行(不支持访问浏览器的对象,例如Document等浏览器特有的对象。)
您也可以将您编写的配置文件共享给其他用户或电脑上的采集器使用哦
开启使用
如下图,勾选【开启自定义规则采集】即可开启自定义的字段采集。
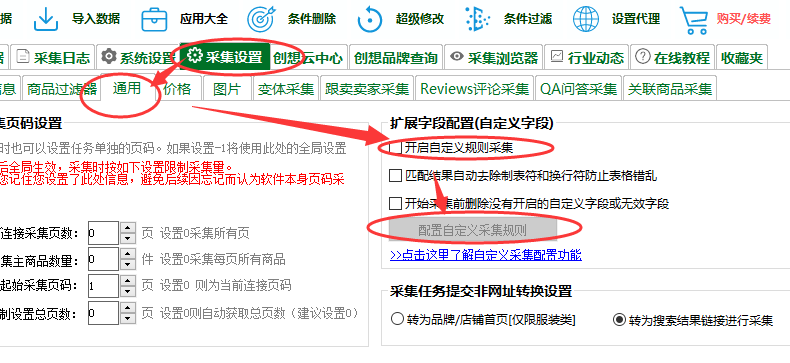
功能介绍
如下图,您可以配置采集规则根据需求进行采集。
左边栏中列出了当前安装或配置的自定义字段,勾选则表示开启,未勾选则表示未开启。
开启后的字段,将在采集时自动列出,并将数据按条件提取出来写在表格中。
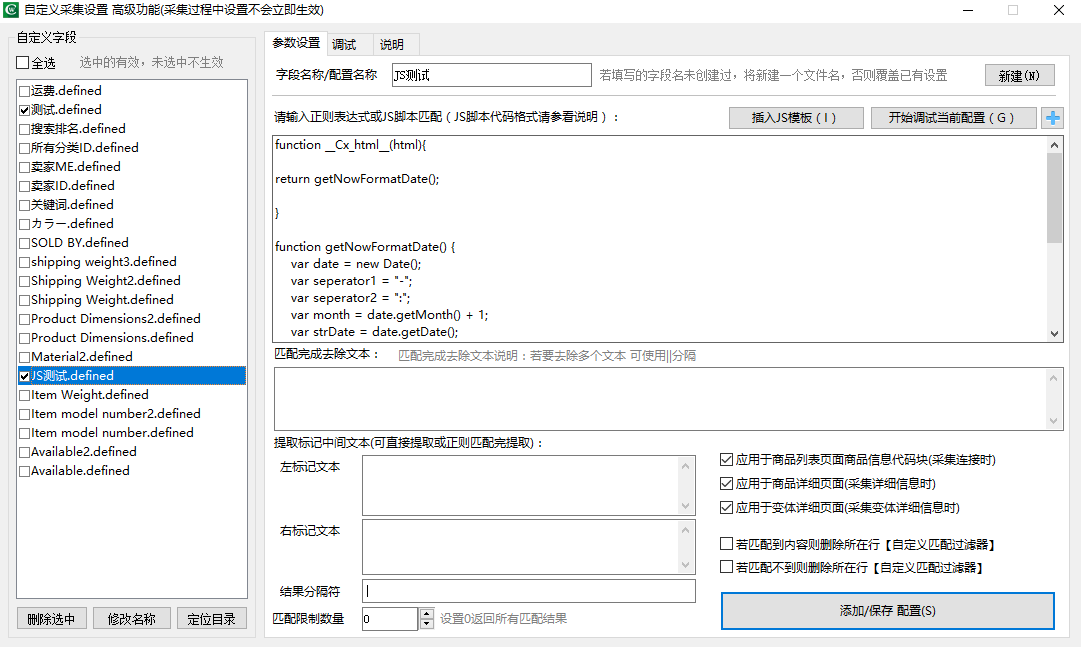
自定义规则配置快速介绍
- 点击“新建”按钮,新建一个自定义字段配置,输入自定义字段名称,该名称将是采集时表头的名称。
- 然后设置正则表达式或简单标记符或JS脚本,关于正则表达式、JS脚本的使用,可以到百度或谷歌自行搜索学习相关内容。(也可以直接使用左右文本标记提取,无需正则表达式)也可以自己编写JS脚本代码,通过JS脚本处理文本。
- 输入完提取的正则表达式后,可再次对正则表达式提取的内容进行二次处理,例如去除文本功能、左右标记取中间功能。同时可以限制正则返回的数量、应用的采集页面(商品列表页、商品详细页、变体详细页),同时支持调试,可将要调试的网页源码复制粘贴到调试栏目中,点运行匹配,即可查看匹配后的结果。
- 配置完自定义字段,点击“添加/保存配置”按钮即可保存该自定义字段,然后勾选即可生效。
使用他人共享的自定义规则
- 得到创想亚马逊ASIN采集器自定义字段配置文件(.defined文件)
- 进入自定义字段配置窗口
- 点击定位目录,将.defined自定义字段文件粘贴到这里
- 重新打开自定义字段窗口,勾选需要开启的字段重新采集即可看到所需数据。
(注意有些字段需要采集详细信息时才可用)
注意:设置完成自定义字段后需要开始采集数据时即可看到自定义字段列哦。
自定义字段采集范围说明
- 开启了“应用于商品列表页面”,则批量采集(采集店铺列表、搜索结果列表等页面)时才会建立该列
- 开启了“应用于商品详细页面”,则采集详细信息(商品详情页)时才会建立该列
- 开启了“应用于变体详细页面”,则采集变体详细信息时才会建立该列
以上字段生效范围可同时开启。
自定义字段过滤功能说明
- 若开启了“若匹配到内容删除所在行”,则此自定义配置抓取到数据,就会删除所在行商品
- 若开启了“若匹配不到内容删除所在行”,则此自定义配置抓取不到数据,就会删除所在行商品
通过自定义匹配,可实现更多复杂便捷的过滤筛选需求。
自定义字段配置实战
共有三种方法提取指定文本,不同方法提取能力不同,适用场景不同:
第一种:左右文本标记简单提取(此方法适合简单的文本提取,配置简单)
第二种:正则提取(适合懂正则表达式的用户配置,能匹配提取大部分文本数据)
第三种:JS脚本代码提取(适合理解JS脚本的用户配置,99%的页面上的信息数据都能通过JS脚本准确提取)
下面,我们来分别简单介绍一下三种方法。
例子:
首先我们先阐述一下需求场景
适合简单的提取,例如提取产品尺寸信息(该字段目前旗舰版用户已默认支持),我们用自定义字段来进行采集。
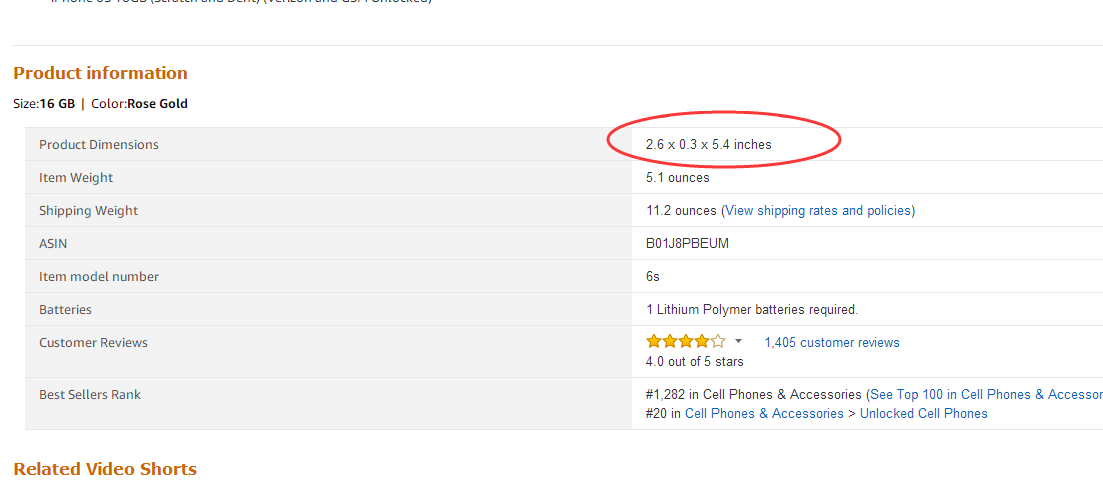
第一步: 在浏览器中进入商品网页,点击右键,查看该页面的源码。
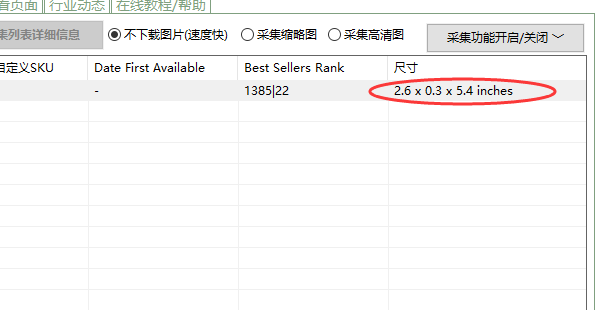
第二步:按下CTRL+F,搜索2.6 x 0.3 x 5.4 inches字符串,定位到该字符串的位置
第三步:
定位到该字符串的位置,如下图:

下面我们利用前面提到的三种方法来进行采集。
第一种:左右文本标记简单提取
左右文本标记比较简单,仅需要左边文本和右边文本,即可定位中间的文本,即要提取的数据。
配置如下图:
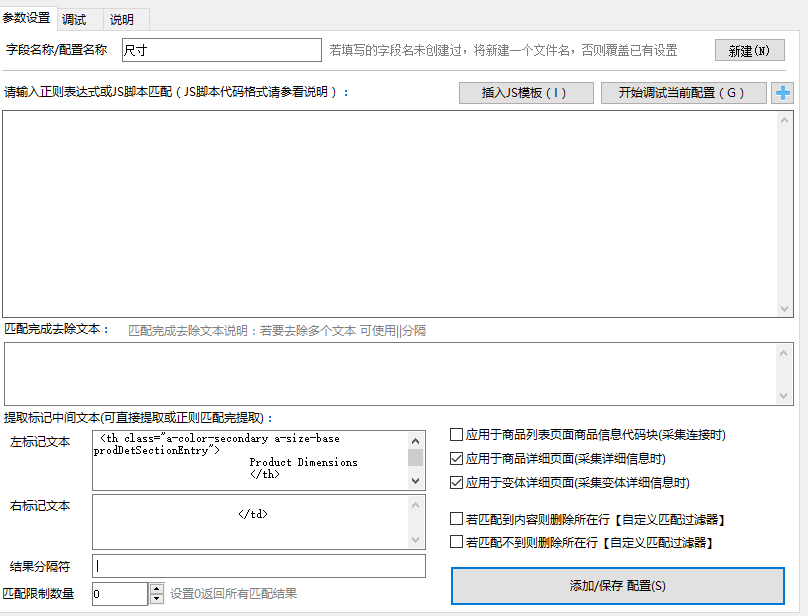
将2.6 x 0.3 x 5.4 inches字符串左右的代码文本复制到 左标记文本和 右标记文本中,即可提取到体积。我们可以复制所有源码调试。如下图:
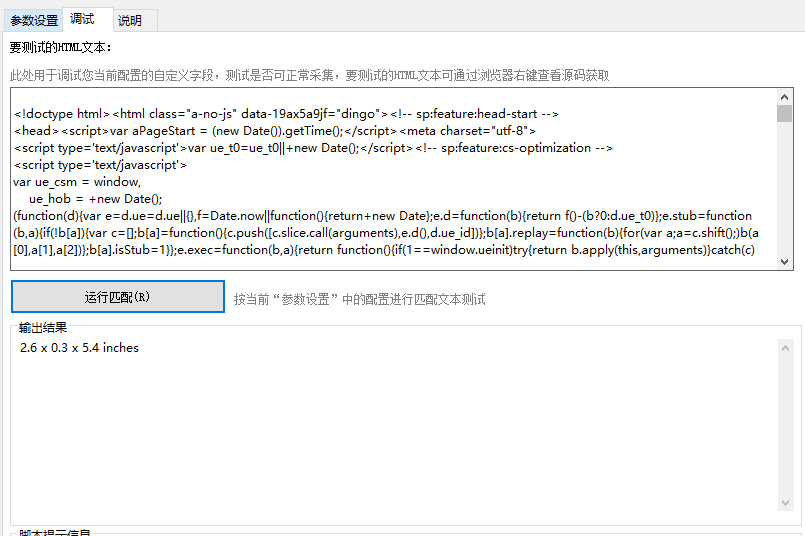
可以看到调试成功,下面我们保存,并勾选开启这个字段,进行采集。如下图:
注意,提取的左右文本换行符回车键等字符都必须复制,往往少复制一个字都会导致匹配不上,因此请注意字符不要复制少。
第二种:利用正则表达式提取
有关正则表达式可查看网络上相关教程,这里不再叙述
按下图设置
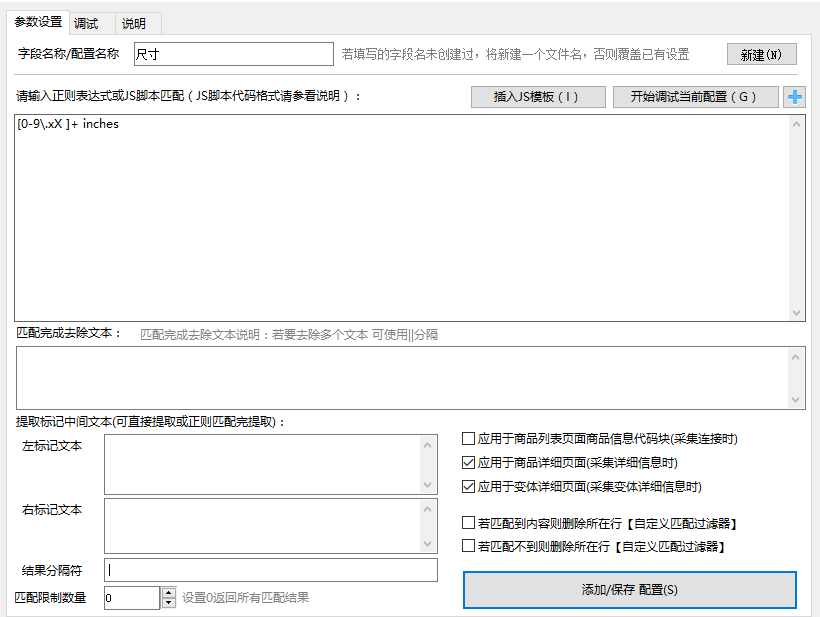
可以看到成功采集到了数据:
第三种:利用JS脚本提取
首先我们插入JS模板函数,点击插入JS模板按钮。即可插入,如下图:
此处的JS脚本不支持调用document对象和window对象,以及浏览器的NODE API,仅支持常规JS代码,例如文本提取、字符串处理、正则匹配等函数

只需要在__Cx_html__函数中,编写处理提取文本的代码或其他需要的代码,即可实现更复杂的数据提取。
function __Cx_html__(html){
//此处写相关处理代码并return返回处理完的数据
}
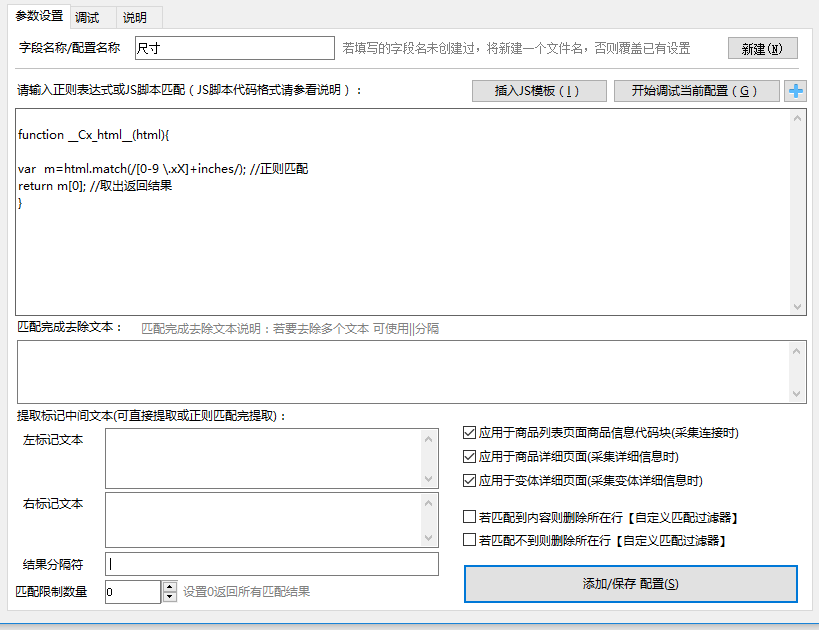
我们利用JS的正则处理函数,进行提取,编写JS代码如下:
function __Cx_html__(html){
var m=html.match(/[0-9 \.xX]+inches/); //正则匹配
return m[0]; //取出返回结果
}
如下图:
JS脚本代码运行错误以及错误提示,可在调试中进行调试查看。
通过JS代码来提取指定信息并输出。如下图:
小技巧:JS脚本不仅可以用于文本提取,还可以按不同数据对应不同场景返回数据到表格,例如可用时间函数,返回此数据采集的时间、返回随机数等等。功能大大扩展。
JS提取功能还在测试中,如有问题请联系我们反馈
为什么已经配置了自定义字段,但是仍然无法显示结果?
- 请先在【采集设置】【通用】【扩展字段配置】勾选【开启自定义规则采集】
- 检查您的自定义配置,匹配范围是否设置,例如采集详细信息时匹配,但是没有勾选采集详细信息时应用。在【自定义字段】配置窗口,点击【提取设置】,设置【应用范围】勾选所需采集的范围。
- 检查您的自定义字段是否能够正常匹配调试
- 采集商品时,采集的页面可能会和您浏览器显示的页面不一样,导致HTML也不一样,匹配可能也匹配不上,您可以直接用JS 返回全部html代码,并采集,采集时获取到采集软件采集的HTML代码后,再调试尝试解决。
- 如果您应用范围设置【采集列表页商品代码块】时,采集列表页时,用于匹配的文本是每个商品的HTML代码,而不是整页的HTML代码,这点请注意。
附录
常用正则表达式匹配:
美国站匹配重量正则表达式:([0-9\.]+ ounces)|([0-9\.]+ pounds)
美国站匹配尺寸正则表达式:[0-9\. xX]+ inches
附赠已经写好的自定义规则文件
使用方法:如下文件下载后,请在自定义规则配置工具中,点“定位目录”,将文件粘贴到此目录中,然后重新打开自定义规则配置刷新即可显示,然后选中即可生效哦
请查看这里,下载我们预设的配置文件 : https://blog.cxsup.com/archives/1531
🔒 完整内容限付费会员查看
本文章限“创想亚马逊采集软件”付费用户查看。
请在创想亚马逊采集软件中按【F1键】查看注册邮箱和机器码,粘贴登录即可查看。
如果您是试用版用户请联系客服索取临时密码。
版权声明:付费用户专属帮助文档,严禁复制、镜像、公开给他人,否则冻结账号并追究侵权损害。